Platform Behavior
This document describes the current safeguards, imposed limits and what can happen when your integration flows reach these limits.
Introduction
Every running system has limitation and safeguards in place to prevent abuse and ensure stability. Your own computer has it, your email service has it. Our platform is not an exception.
We have imposed limits and safeguards in place to ensure stability of the system for every company, every user and every integration flow. If one of your integration flows is misbehaving for any reason, it should not affect your other integration flows, your entire operations or other users in the system.
In this document we provide information about the current safeguards, imposed limits and what can happen when your integration flows reach these limits. We describe common errors connected to these limits and the ways to prevent or address them.
Default Limits
The table below lists elastic.io platform parameters which you can configure to impose limits along with their default values.
| Limit Name | Description | Value |
|---|---|---|
| Queue message number | Processing queue message count limit. More information in Messaging Queue Limits. |
75000 |
| Queue message size | Processing queue combined size limit in megabytes (MB). More information in Messaging Queue Limits. |
200MB |
| Outgoing message size | Total size of outgoing message from any integration step in megabytes (MB). |
10MB |
| Error Retention | The limit on Number of Errors the platform will display in case your integration flow starts spamming the system. After this limit is reached errors will not be shown. More information in Error Retention policy. |
1000 |
| Sample retrieval timeout | Time in minutes that the platform will wait during the data sample retrieval in the flow step design. After this the process will stop with a timeout error. |
1min |
| Limited Workspaces | Time in hours until flows stopped in Limited Workspaces. |
8h |
| Container RAM memory | Total processing memory (RAM memory) in megabytes (MB) allocated to each running pod in Kubernetes cluster for Node.js and Java based components. Can cause OOMKilled error if exceeded. |
1024 |
| Container logs TTL | The number of days for which container information is stored on the platform. |
30d |
| Executions TTL | The number of days during which execution details are stored on the platform. |
30d |
| Logs TTL | The time in days that logs information is stored on the platform. |
14d |
| Input messages TTL | The time in days that the messages that led to the error are stored on the platform. |
5d |
Please note: These are default values, but some of them can be changed, e.g. RAM memory.
Platform has set limitations on accepting, processing and exporting attachments. Please check the attachment limitations page for more details.
Messaging Queue Limits
The messages in your integration flow steps go through the queues so that the platform can process them in their turns. Each step in your active integration flow has a dedicated messaging queue. The platform imposes both Queue message number and Queue message size limits to each of these queues.
Please Note : These limits ensure the stability of processing queue engine - the RabbitMQ. We can increase these limits for the whole system (not recommended) or for individual flows (recommended) if your use-case requires this. Please get in touch with us to discuss your use-case.
When the step queues in your integration flow reach any of these two limits, platform will stop processing messages until the message number or combined queue size drops from the set limit according to Dynamic Flow Control mechanism. This ensures the stability of RabbitMQ from one side but it also ensures that no messages get lost.
To take advantage of this mechanism, your component must use the Sailor version
supporting Dynamic Flow Control mechanism. In particular, you must build your
Node.js component with Sailor version 2.6.7+ or the Java component with Sailor
version 3.1.0+.
In case when even one of your integration flow steps uses a component with older Sailor version, the following will happen:
- When the message count reaches 80% of the queue limit (60K), the platform will suspend your integration flow to ensure the stability.
- Any new messages getting to already overflowed queues can get lost.
Flow Suspension
In some rare cases platform can suspend your flow. This safeguard ensures the stability of the system in edge cases when all other safeguards fail. The suspension is more of a pause, than a stop. You will receive an email informing you about the flow suspension. You can then resume your flow or stop it for further investigation.
Flows Stopped in Limited Workspaces
To keep the processing resources in check, the platform will stop any integration flows in limited workspaces after the set time limit. Any non-processed messages will be dropped.
You can login and start your flows again to reset this interval. If your use case requires longer and uninterrupted runs contact our support to convert your workspace to production type.
Please Note Limited workspaces are for testing and trying the platform.
Component failed to start
Once in a while you might face with an error like Component failed to start.
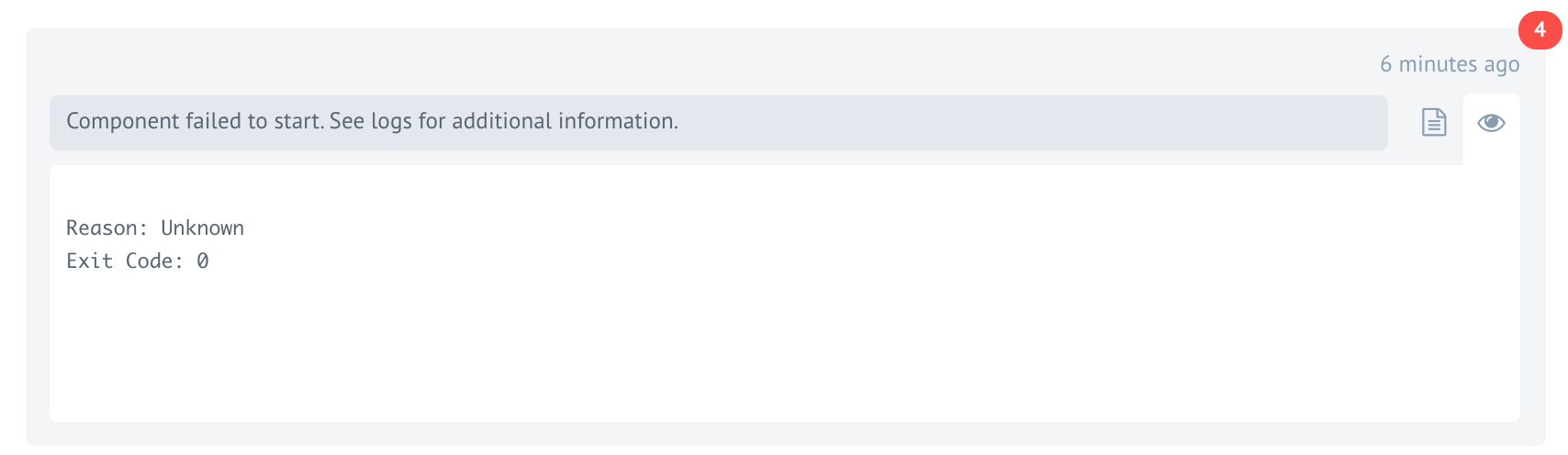
Usually this is not that bad as you might think. The platform will automatically restart the component to recover the process without any impact to your integration flow. In majority of cases this recovery process takes less than a second and you might notice this error afterwards.
The reasons for this error may differ. In most cases this error will happen due to over-subscription of processes in the Kubernetes cluster node where this process was initially started. Kubernetes decided to remove the pod from overcrowded node and start it on less crowded node. This is part of the normal operations in Kubernetes cluster and it can happen at fraction of the second.
If these kinds of errors keep happening, please submit a ticket to the platform support as described here to get help in troubleshooting.
Component run out of memory
Every component runs in a unique container pod in the Kubernetes cluster and if the component code consumes more memory than the set limit, the platform will terminate this process and you will see the Component run out of memory and terminated error.
You can check Component logs the same way as shown here,
to see the clear reason OOMKilled with Exit code 137:
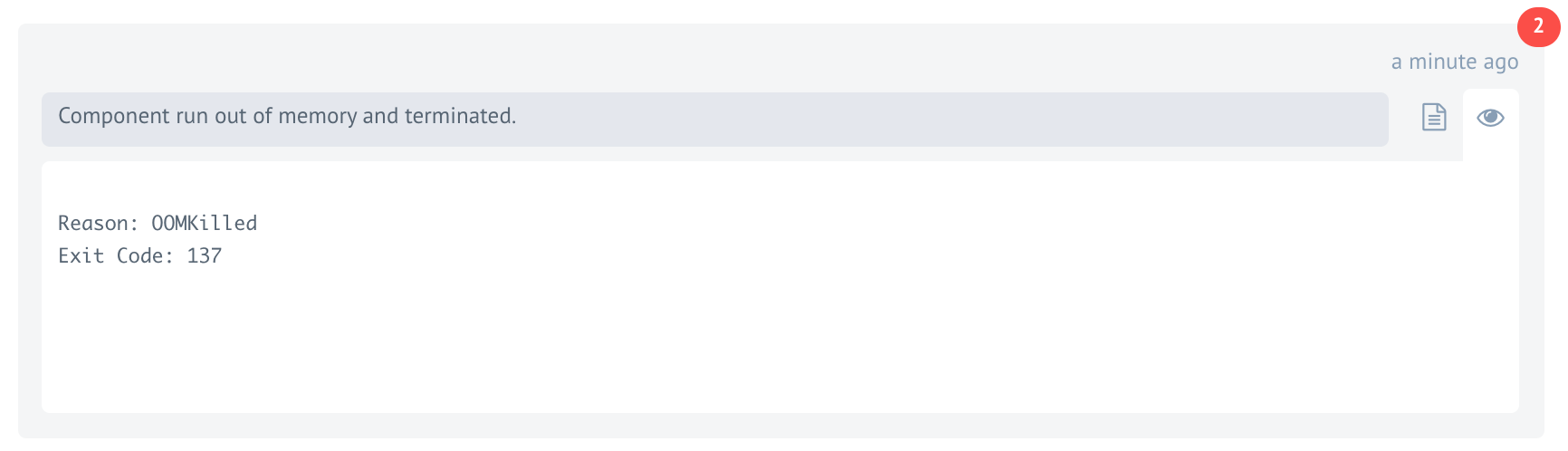
In this case, the message can be lost. If one or more steps of your integration flow constantly fail then you must consider following one or more of the recommendations.
Optimise component or integration logic
Logically the component can run out of processing memory during the processing of an incoming data in combination with internally created data. For example a large array of data gets split creating even larger data to process.
If this is your component then consider optimising the data processing. Try to process less amount of data at each execution instance. Run some local tests with a typical data to determine what is going on. It might be a memory leak in your component code.
If this is system provided component, then you can examine your integration logic. Try to send less data to the affected integration step.
You have checked and done everything above but the integration step fails with
OOMKilled. Consider the fact that your might not see the complete incoming data because
of the Passthrough. It could serve as a
tipping point here. You can disable the passthrough if that makes sense for your use-case and see if out of memory error has disappeared.
Give more processing memory
By default platform has set limits on allocated and requested processing memory for each pod in the Kubernetes cluster. However, in some cases giving more processing memory (RAM memory) is the only way to solve out of memory errors. In general, Java based components require more RAM memory than Node.js based components.
We have set recommendations for each component for the minimum amount of RAM memory to use. Check if your component has such requirement and set it accordingly.
To set the custom RAM memory limits on any component an environment variable
EIO_REQUIRED_RAM_MB and the value in megabytes (MB) is set.
Please Note: Use of environment variable to increase the limits higher than recommended should be considered as a last resort. Please follow instructions below strictly.
- If you are setting environment variable to test the scenario in one flow, consider using
EIO_REQUIRED_RAM_MB_FLOW_{Flow_ID}variable. This way the component will use more RAM memory only in one flow and you will not suddenly increase the RAM memory consumption for everybody who uses the component. - Consider increasing the RAM memory incrementally. Set 2048 first and test your flow.
- If you are near to 4GB (4096) and still getting
OOMKillederror, then you are doing something wrong. You need to revisit your component’s code or integration logic. - If you need RAM memory increase on one of the system provided components. Get in touch with support to discuss your use case.
Syntax Errors
This is not a Platform error per se, but it happens frequently if data is not handled correctly. And your Flows won’t suffer from this issue. Most likely, you will still see the problem in Component logs and be able to fix it. Otherwise, escalate the issue to the platform vendor via support. You can find info on applying for support here.